
Sự phát triển của Machine learning đã có nhiều bước đột phá và được sử dụng rộng rãi trong những năm gần đây. Với sự giúp đỡ của nhiều tools và frameworks để đơn giản hóa việc inference và logging service. Nhưng thông thường, bước triển khai ML service thường bị bỏ qua và không được biết đến rộng rãi như dựng mô hình ML. Tuy nhiên trong ML cycle, traing ML model chỉ chiếm 20 phần trăm của dự án. Đặc biệt, khi deploy mô hình AI cho người dùng cuối thường khá sơ sài và target chính để demo ở MVC phase. Do đó, làm thế nào chúng ta có thể quản lý mô hình AI trong thực tế và làm cho AI cycle được triển khai nhanh chóng. Chúng ta sẽ đi sâu vào một số phương pháp best practices trong phát triển phần mềm và cách được ứng dụng vào dự án AI tương ứng.
Introduction
Mình chọn bài toàn phân tích ngữ nghĩa của twitter cho hands-on Project vì bài toàn khá đơn giản và visulize được một pipeline cụ thể trong dự án ML

Ý tưởng của dự án là lấy dữ liệu từ của tweet của user và phân tính nội dung tình cảm của nó. Sau đó, tổng hợp văn bản cảm xúc từ từng user để phân tích thêm cảm xúc của họ trong những đoạn tweet gần đây.
Choosing the right format model
Mô hình được chọn lựa là transformer roberta model để analyst sentiment của text Đầu tiên, chúng ta sẽ tìm định dạng để mô hình được tối ưu hóa nhằm giảm thiểu thời gian tính toán và chuẩn hóa cách load mô hình. Cho mô hình pytorch, mình dùng torch script để transform mô hình về định dạng jit format. Code transform mọi người có thể tìm ở đây github, và bạn có thể run lại nếu muốn.

Khả năng tính toán không được cải thiện nhiều ở CPU usage nhưng GPU model cho ta thấy được the runtime of torchscript tốt hơn nhiều so với mô hình thuần PyTorch.
Code load model rất đơn giản và được standardize torch.jit.load, mô hình cũng được lưu thành ScriptModule format và sẽ không thay đổi cách load kể cả khi mình thay đổi hoàn toàn model.
Để tối ưu hóa hơn nữa khả năng tính toán của mô hình, các kỹ thuật như quantization hoặc pruning có thể được áp dụng nhưng yêu cầu đi sâu vào nghiên cứu kiến trúc mô hình và mỗi kiến trúc có phương pháp pruning riêng. TVM framework có thể được sử dụng để tự động lựa chọn optmized mô hình nhưng cần nhiều thời gian và tài nguyên GPU để chọn trình biên dịch và điều chỉnh kiến trúc phù hợp. Quá trình tối ưu hóa thật rất phức tạp và refer một blog dành riêng của nó và mình sẽ đề cập khi khác. Đối với mô hình PyTorch, cách đơn giản nhất là chuyển đổi sang định dạng JIT và dễ dàng đạt được hiệu suất 5-> 10%
RestAPI and Project Template
Để triển khai AI model, giao thức phổ biến nhất là Rest API và mình sẽ sử dụng FastAPI cho serving framwork. FastAPI là framework đứng thứ 3 trong danh sách framework được yêu thích nhất ở Stack Overflow 2021 Developer Survey và hỗ trợ OpenAPI. Hơn nữa, sự kết hợp giữa Pydantic và FastAPI hỗ trợ typing system và readability, mình khuyến khích ai đang code python thì đều nên dùng thử.
-
Auto-generated docs and simple front end for your API allow you to examine and interact with your endpoints with essentially no added work or tools
-
Feature rich and performant
-
Tight pairing with Pydantic makes specifying and validating data models easy
Project code style
Việc coding trong dự án phải được tuân theo tiêu chuẩn và cần constantly kiểm tra xem thành viên có vi phạm tiêu chuẩn đã đề ra hay không. Code để autocheck format code đã được mình viết sẵn ở format.sh và lint.sh trong github. Standard tiêu chuẩn mình thường chọn lựa là google python code style và dưới đây là vài cách set tiêu chuẩn ở config file
Environment managment
Sử dụng biến môi trường sẽ cho phép chúng ta dễ dàng chuyển đổi môi trường code mà không cần phải define sẵn ở code file. Nó cũng sẽ giữ cho các tên và giá trị biến môi trường của bạn được tách biệt với cùng một dự án sử dụng.
Một trong những lợi ích của việc sử dụng tệp .env là giúp chúng ta dễ dàng hơn nhiều để phát triển với các biến môi trường từ rất sớm. Suy nghĩ về những điều này ở giai đoạn đầu dự án sẽ giúp bạn chuẩn bị ứng dụng của mình để đưa vào production tốt hơn.
AI project tips
Quá trình tải mô hình Deep Learning lên ram thường rất lâu và tốn nhiều resource. Mình thường thấy các dự án AI nhiều bạn thường load model ở ngay code endpoint requrest làm khả năng tính toán rất chậm vì cần phải load model trước. Cách tốt nhất là chúng ta nên load model chỉ một lần ở app context và pass object đó qua các request obj.
Feature Store
AI service thường cần rất nhiều tài nguyên và khả năng tính toán, để giữ được một service healthy và low latency API. Chúng ta cần sử dụng một feature-store db để lưu trữ và mang lại trải nghiệm tốt hơn cho người dùng.
Redis database thường được chọn làm nền tảng cho feature-store, nhờ khả năng cung cấp độ trễ cực thấp với thông lượng cao trên quy mô lớn.
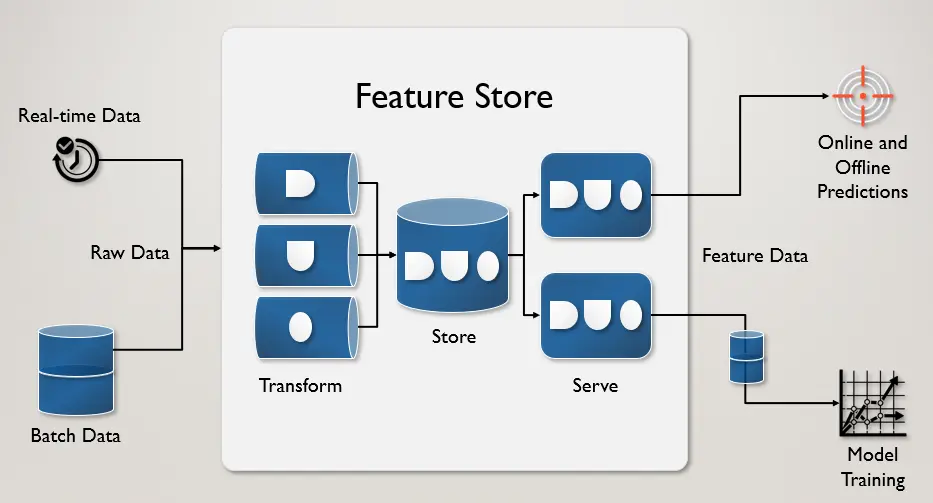
Mình sẽ sử dụng redis làm feature-store để lưu trữ dữ liệu và phân phát nếu dự đoán cho một tweet thể đã được thực hiện. Bạn có thể mở rộng feature-store khác dựa trên backend base class
Đây là một đoạn code sử dụng feature-store để dựng API
Writing data to Feature Store
Trong FastAPI, bạn có thể chạy code bên ngoài web context sau khi đã trả lại response. Tính năng này được gọi là background tasks.
Tính năng trên không strong bằng việc sử dụng thư viện tác vụ chạy nền như Celery. Thay vào đó, background tasks là một cách đơn giản để chạy code bên ngoài yêu cầu của web, rất phù hợp cho những việc như cập nhật bộ nhớ cache.
Khi bạn gọi add_task(),bạn truyền vào một hàm và danh sách các arguments. Ở đây, mình sẽ chuyền vào function set_cache(). Function này lưu kết quả dự đoán vào Redis. Hãy xem nó hoạt động như thế nào nhé:
Đầu tiên, mình chuẩn hóa dữ liệu thành JSON và lưu nó vào feature_store. Sau đó sử dụng tham số expire để đặt thời gian hết hạn cho dữ liệu là sáu mươi ngày.
Reading Data from Feature Store
Để sử dụng endpoint inference, clients sẽ thực hiện yêu cầu GET đến /inference với link tweet. Sau đó, ta sẽ cố gắng lấy dự đoán từ Feature Store. Nếu dự đoán chưa tồn tại, máy sẽ tính toán dự đoán, trả lại kết quả và sau đó lưu dự đoán đó bên ngoài web context.
Dockerize application
Sau khi xong phần coding, mình sẽ sử dụng Docker để đóng gói project và deploy cho người dùng cuối. Nhưng bản build Docker truyền thống không có hỗ trợ dynamic caching từng lớp và docker size rất lớn nên sẽ tốn rất nhiều resource lẫn tiền nong khi develoment.
Thực tế thì rất phổ biến khi có một Dockerfile để sử dụng cho phát triển (chứa mọi thứ cần thiết để xây dựng ứng dụng), và một bản thu gọn để sử dụng cho production, mà chỉ chứa ứng dụng và chính xác những gì cần thiết để chạy nó. Pattern này đã được gọi là builder pattern. Nhưng duy trì hai file Dockerfile không phải là lý tưởng và rất dễ rối cho developer sử dụng. Để chỉ duy trì trên file docker, giữ kích thước image ở mức thấp và enable caching để tạo lại docker nhanh hơn, ta sẽ sử dụng multi-stage builds để dockerize AI service
Docker image của một dự án AI thường được xây dựng theo ba bước và có thể được xây dựng thành ba images khác nhau:
- Tải mô hình AI model
- Cài đặt framework cần thiết
- Triển khải AI model
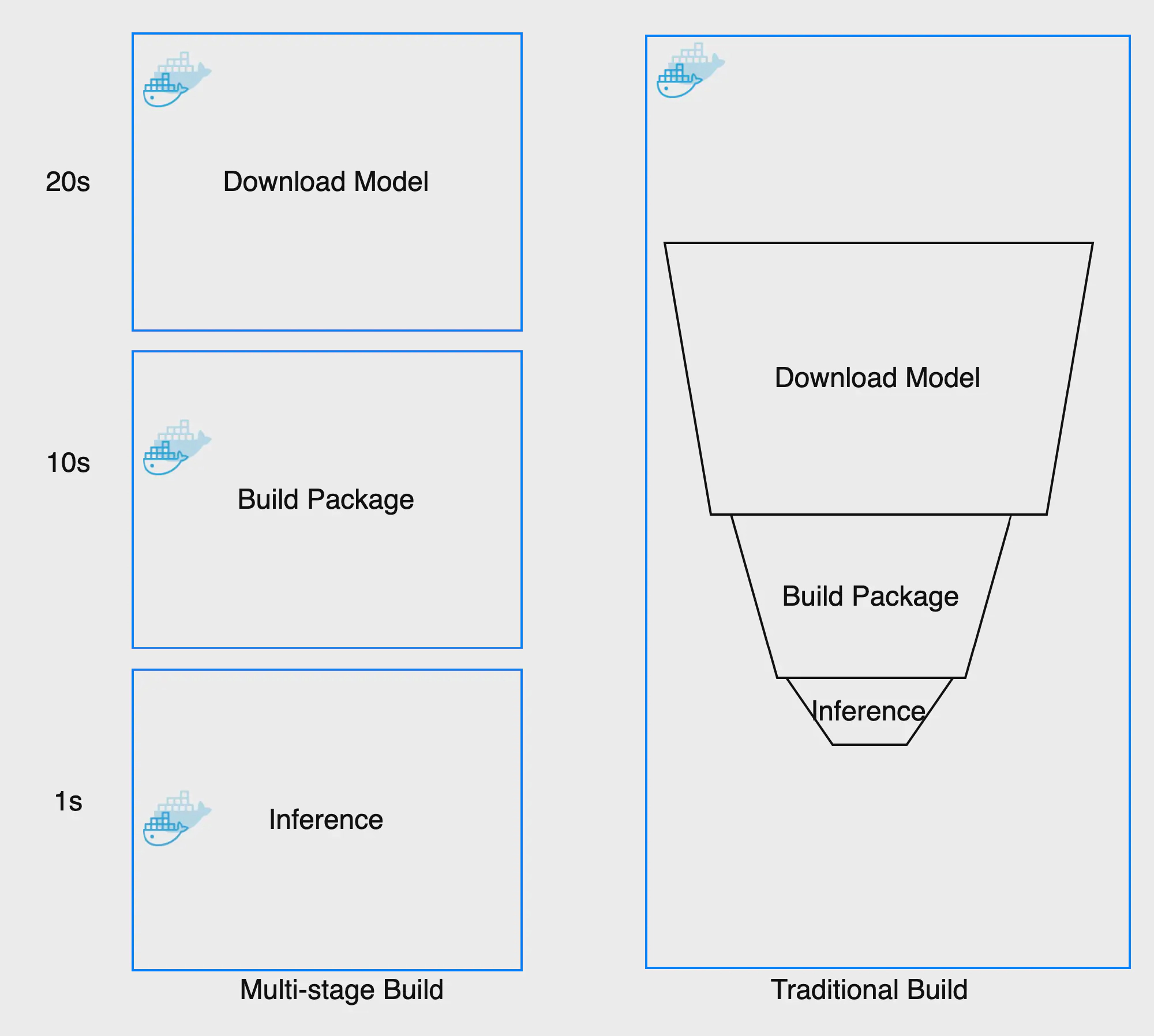
Cách tiếp cận truyền thống được xây dựng như một chuỗi các lớp và mỗi lớp xây dựng dựa trên lớp trước đó. Đó là lý do tại sao khi ta tăng phiên bản của mô hình AI thì phải xây dựng lại tất cả các lớp docker trước đó và không thể tận dụng các lớp độc lập ngay cả khi chúng ta chỉ thay đổi mô hình AI không liên quan đến cài đặt framework step.
Multi-stage build cho phép chúng ta phân tách từng bước để tách riêng docker có thể để sử dụng lại và build một cách độc lập. Việc thực hiện từng bước có thể được lưu trong bộ nhớ cache và chỉ cần xây dựng lại những gì mà ta thay đổi. Dưới đây là một số so sánh giữa xây dựng truyền thống và xây dựng nhiều giai đoạn:
| Multi-stage | Traditional | Saving | |
|---|---|---|---|
| Change AI model | 11s | 31s | 64.5% |
| Last Image size | 2.75GB | 5.4GB | 49% |
Như bạn có thể thấy, Multi-stage build giúp tiết kiệm rất nhiều thời gian trong việc xây dựng hình ảnh và image size nhỏ hơn rất nhiều. Mình thường thấy các team chỉ xây dựng Docker đơn giản rồi cho Live vì theo lý luận của họ là docker image to nhỏ cũng không làm app chạy nhanh hơn. Thật sự mình rất thất vọng với lối suy nghĩ như vậy và không hề nói quá về việc CI-CD chậm khiến lượng thời gian lãng phí chờ đợi của developer có thể lên tới 10 nghìn USD / năm ngay cả đối với các nhóm nhỏ. Khi CI-CD cần tốn 10 phút để hoàn thành thì ta đã tốn hơn ++10 phút ở developer time.

Docker multi-stage steps có thể được mô tả trong build.sh và build-push để upload docker image. Để có hướng dẫn chi tiết hơn về multi-stage docker, bạn nên xem full guide
Reliable service
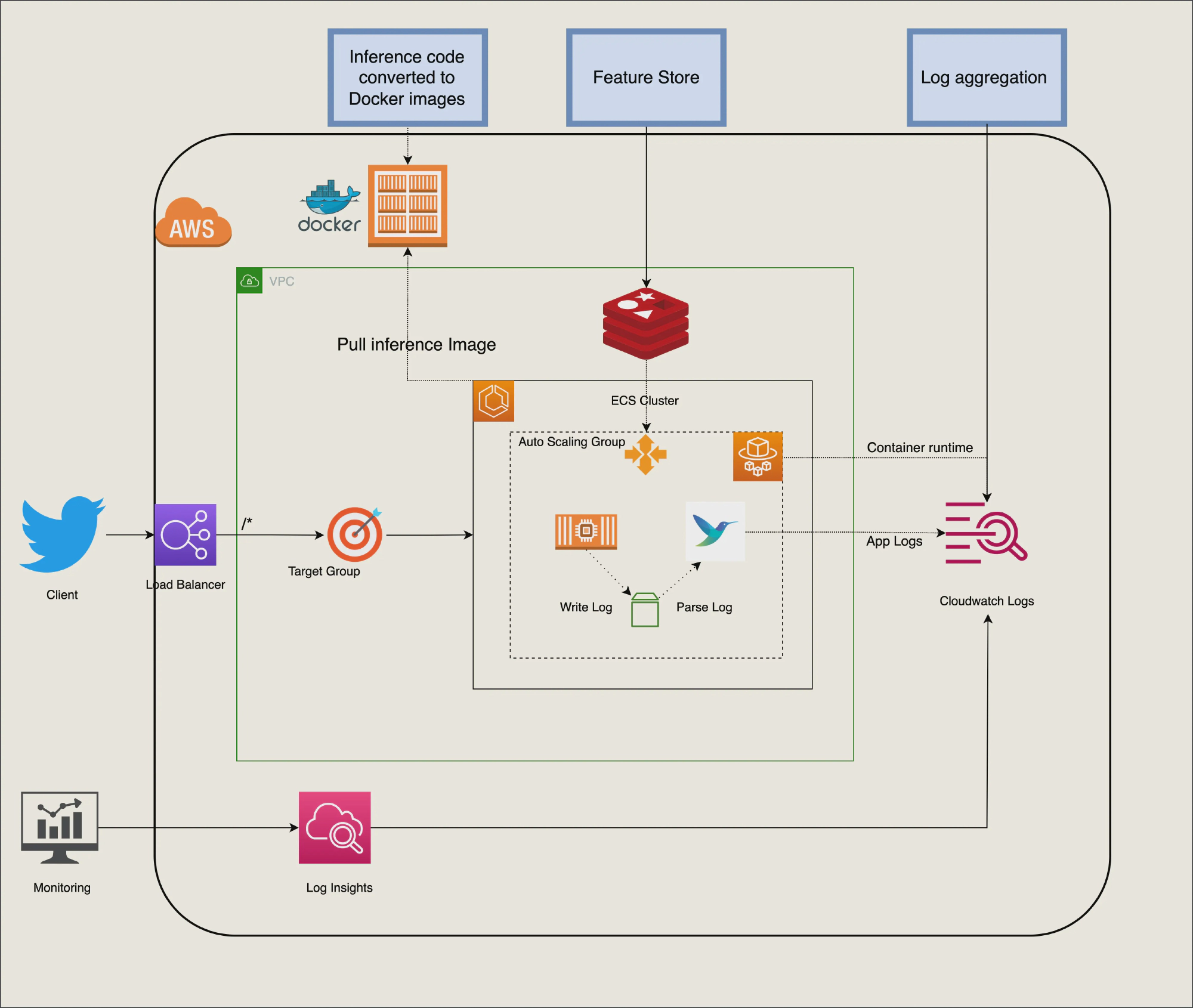
Khi bạn đang xây dựng một ứng dụng phần mềm hoặc một dịch vụ, mình chắc chắn rằng bạn đã nghe đến những keyword như: scalability, maintainability, and reliability. Đặc biệt trong dự án AI thường để dự đoán unknow. Việc xây dựng một dịch vụ đáng tin cậy và SLA 99.99% uptime về cơ bản là rất khó ngay cả đối với một team lớn. Để tránh các khó khăn trong việc tự xây dựng mọi thứ, Cloud vendor nên là lựa chọn đầu tiên để triển khai và mở rộng ứng dụng. Đối với quy mô nhóm vừa và nhỏ, dịch vụ AWS ECS và fargate là ứng cử viên tốt nhất để cung cấp ứng dụng của bạn với chi phí tối ưu và ít cần bảo trì nhất có thể, bạn có thể tìm thêm trong previous blog mà mình đã nói về mức độ phù hợp và ổn định của kiến trúc này đối với team vừa và nhỏ.
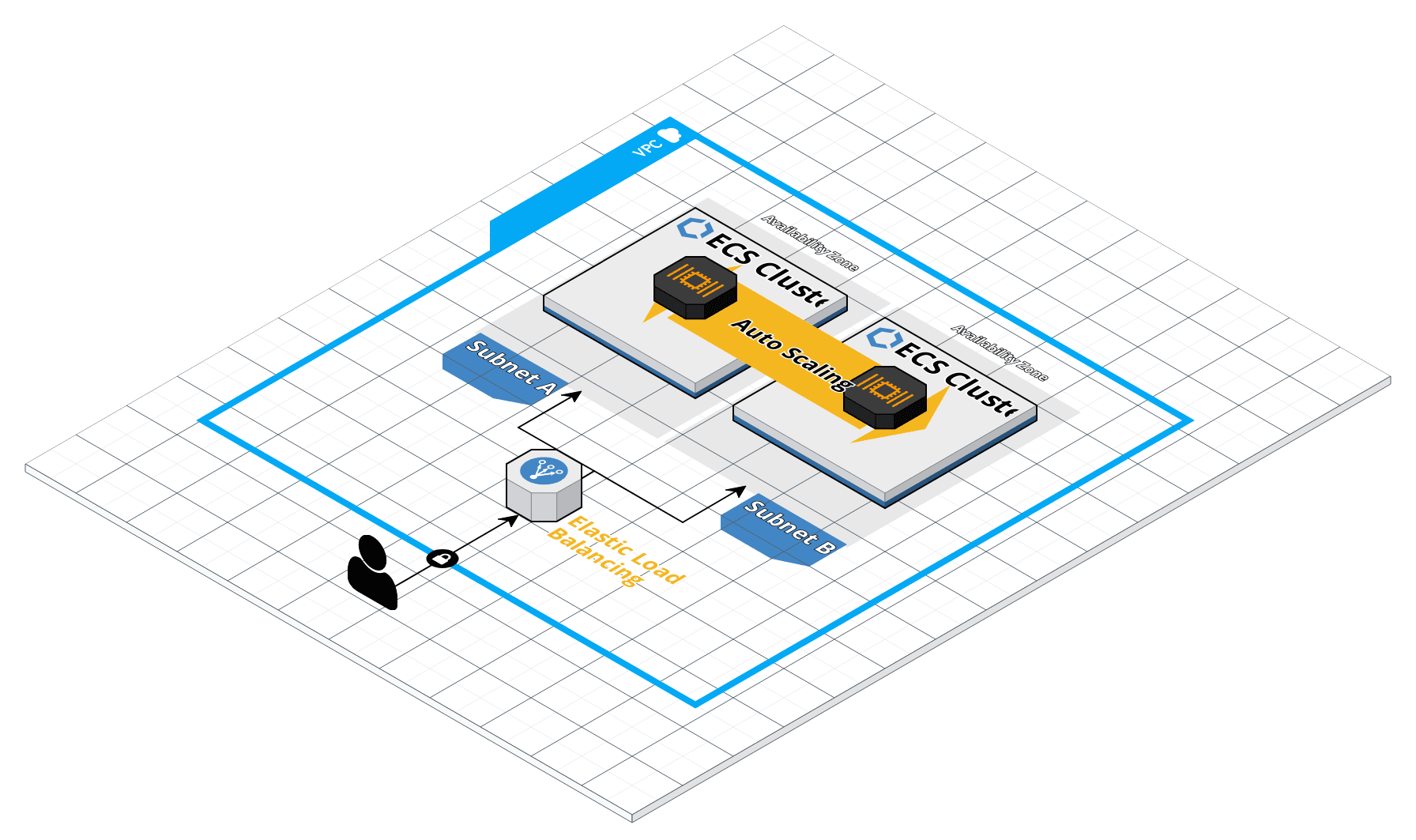
Bằng cách tận dụng Cloud Vendor và Serverless, chúng ta có thể giảm thiểu những sai sót có thể xảy ra trong ứng dụng AI như sau:
-
Reliability: Fargate cho phép chúng ta tập trung vào việc xây dựng các ứng dụng mà không cần quản lý máy chủ. Mọi vấn đề về phần cứng hoặc phần mềm chưa biết khiến ứng dụng không hoạt động sẽ được thông báo và thay thế. ECS control plan sẽ loại bỏ node bị lỗi và xây dựng lại bỏ mới cho cluster thay cho developer.
-
Scalability: AWS Auto Scaling giám sát các ứng dụng và tự động điều chỉnh dung lượng để duy trì hiệu suất ổn định, có thể dự đoán được với chi phí thấp nhất có thể và năng động theo lưu lượng truy cập.
-
Maintainability: AWS CloudFormation dưới dạng IAC giúp thành lập mô hình và thiết lập các tài nguyên AWS của mình để chúng ta có thể dành ít thời gian hơn để quản lý các tài nguyên đó và nhiều thời gian hơn để tập trung vào các ứng dụng chạy trong AWS.
Các bước mô tả để triển khai ứng dụng AI cho ECS được đề cập ở đây
Monitoring and aggregate log
CloudWatch giúp thu thập dữ liệu giám sát và hoạt động dưới dạng logs, metrics, và events, đồng thời trực quan hóa dữ liệu đó bằng cách sử dụng trang dashboard để bạn có thể có được cái nhìn thống nhất về các tài nguyên, ứng dụng và dịch vụ chạy trên AWS của mình.
Các keys monitoring metric ở AI service:
- CPU and Ram usage
- Task autoscaling
- Feature Store hits
- Failure rate
- Logging
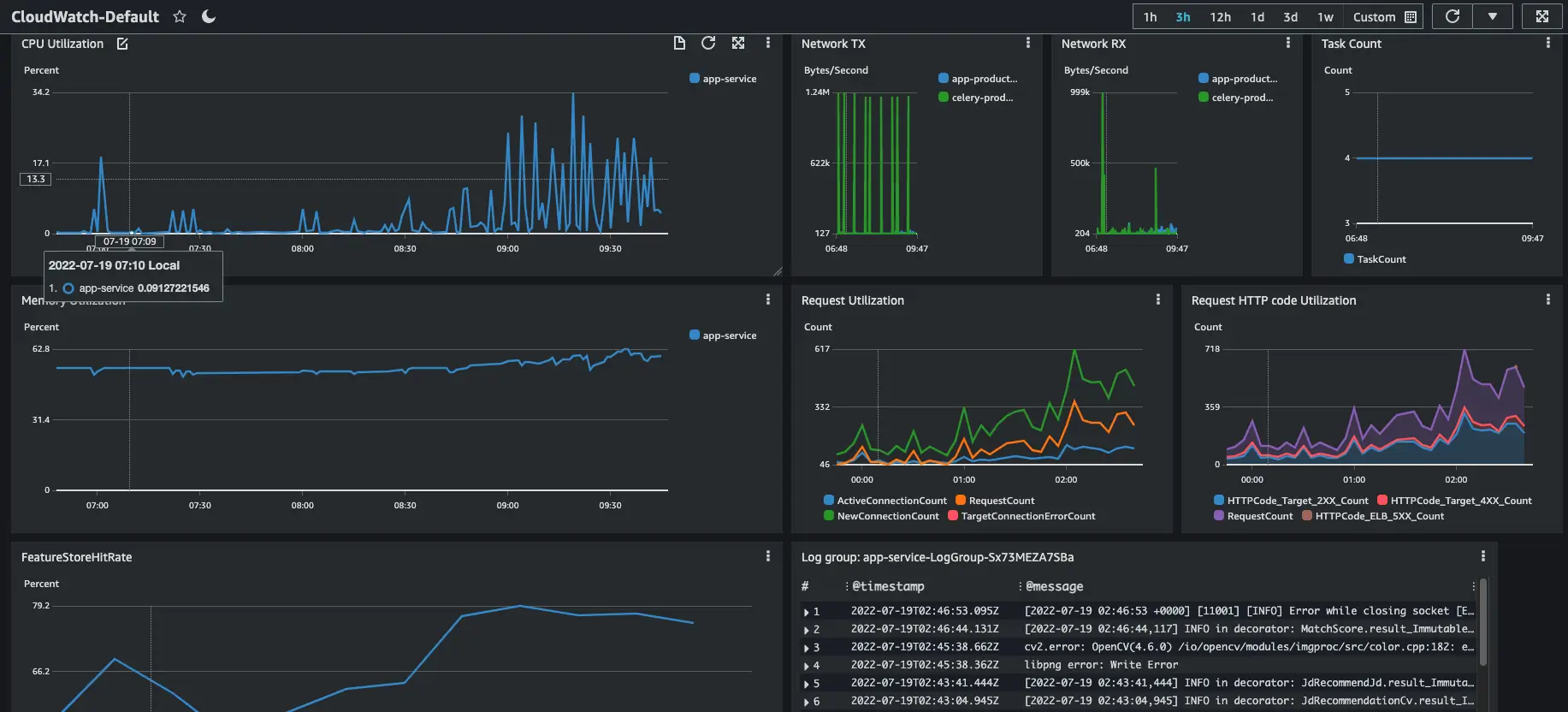
Ta có thể visualize sentiment về tweet mỗi người dùng bằng cách sử dụng feature store. Code cho phần visualize được viết ở đây.


Some afterthought
-
Chúng ta chưa nói về mô hình thử nghiệm A/B vì A/B test rất tốn kém cả về chi phí nền tảng và nguồn lực developer. Một dự án mới launch không nên quan tâm quá nhiều đến A/B tesngoại trừ trường hợp bạn đã có một vài trăm nghìn người dùng đang hoạt động để thực hiện A/B test hiệu quả.
-
Kubernetes cluster phổ biến hơn ECS nhưng cần bảo trì nhiều hơn và một platform-developer chỉ tập trung vào quản lý cluster. Mình nghĩ rằng AI team nên tập trung vào mô hình và số liệu hơn là quản lý nền tảng, tốt hơn là nên áp dụng Kubernetes trong large-scale training hơn là triển khai mô hình.
-
Data drift và Concept drift là hai khái niệm là rất quan trọng để theo dõi mức độ hiệu quả của mô hình AI của bạn. Nhưng bài blog đã cover khá nhiều concepts nên ta sẽ đi sâu hơn vào các khái niệm này trong một blog khác.
Комментарии